import numpy as np
database = np.array([
{
'id': 'string', # unique identifier for the paper following convention P2_#number
'title': 'string', # title of the paper
'AffiliationCountry': 'string' , #name of country the study was conducted in,
'year': 2018-2024, # year of publication a value between 2018 and 2024
'journal': 'string', # name of the journal the paper was published in
'citations': 0-1000, # number of citations the paper has received - not reported in the paper
'year_since': 3, # number of years since publication - not reported in the paper
'cpy': 0, # number of citations per year - not reported in the paper
'keywords': ['TAM', 'mbanking', 'awareness'], # list of keywords, broken into K1-K10
'abstract': 'string', # abstract of the paper
'F': ['perceived usefulness'], # factors significant in the study, broken into F1-F9
'FN': ['another factor'], # factors not significant in the study, broken into FNS1-FNS4
'limit': ['geographical context'], # limitations of the study, broken into LIMIT1-LIMIT3
'typeofResearch': 'string', # type of research conducted in the study
'methods': ['regression analysis'], # methods used in the study, broken into METHOD1-METHOD4
'theory': ['TAM'] # theories used in the study, broken into THEORY1-THEORY4
'sampleSize': 100, # sample size of the study
'tech': 'string', # main technology studied
'man_theme': 'string', # Theme manually assigned by me
'algo_theme': 'string', # Theme assigned by the algorithm
'decision_Theme': 'string', # Final theme of the paper
'Score_Sig': 0.0, # % of significance for factors
'Score_NOT_Sig': 0.0, # % of non-significance for factors
}
])Algorithmic Approach to Finding Themes
Part 0. Jupyter Notebook
If you want to run the entire code, use the Jupyter notebook on my github page.
Part 1. Data Collection
I downloaded the pdf of all the papers (143), reading them and extracting meta data based on the following:
Idea for future
🤖 Build an Agentic AI application that automates this process.
Part 1.1 Finding Out Themes
First, install the following Python modules. I saved the pdf files’ name in a dictionary like this:
name_of_pdfs = {
'p2_01': "Lonkani et al_2020_A comparative study of trust in mobile banking.pdf",
'p2_02': "Saprikis et al_2022_A comparative study of users versus non-users' behavioral intention towards.pdf",
'p2_03': "Malaquias et al_2021_A cross-country study on intention to use mobile banking.pdf",
'p2_04': "Merhi et al_2019_A cross-cultural study of the intention to use mobile banking between Lebanese.pdf",
'p2_05': "Frimpong et al. - 2020 - A cross‐national investigation of trait antecedent.pdf",
# and so on ...
}Additionally, I defined a dictionary “look up” for all the factors in the dataset with their related theme that looks like this (shortened for this presentation):
theme_of_words = {
'demographic':
list(set(['women', 'woman', 'female', 'men', 'man', 'male', 'sex', 'gender', 'age', 'income',
'demographic variables', 'elderly', 'education', 'gender differences', 'generation y', 'millennial generation',
'millennial', 'gen y', 'gen Z', 'gen alpha', 'gen X', 'boomer', 'babyboomer', 'generation X', 'generation z',
'young consumers',
# A lot more factors ...
])),
#----------------------------------------------------------------------------------------------------------------------------------
'cultural':
list(set(['developing countries','malaysia','transition country','pakistan',
'zakat','developing country','ghana','USA','srilanka', 'sri lanka',
'india','maldives','saudi-arabia','saudi arabia', 'nigeria','thailand','united states',
'yemen','citizenship','zimbabwe','palestine','culture',
'Country perspective',
# ...
])),
#----------------------------------------------------------------------------------------------------------------------------------
'psychological':
list(set(['anxiety','satisfaction','behavior','behaviour','attitudes','attitude','awareness',
'technology anxiety','consumer-behavior','trust','benv','consumer behaviour',
'covid-19 related psychological distress','psychological distress','psychological','distress',
'behavioral','computer anxiety','customer satisfaction', 'cognitive resistance',
# A LOT more ...
]))
,
# ... few other key value pairs corresponding to themes
}I also needed to delete some stop words, and decided to add more words that I knew would be frequently repeated. I also define the lemmer and stemmer.
stop_words = stopwords.words('english')
stop_words.extend(["bank", "banking", "banks",
"mobile", "mbank", "mbanking", "m-bank", "m bank",
"online", "e", "e-bank", "ebank", "mobile banking", "mobile bank",
"adoption", "acceptance", "accept", "theory",
"purpose", "result", "method", #from abstracts
"journal", "volume", "pp", "no", "doi", "http", "https", "et al", "issue",
"technology", "internet", "information system", "international information",
"information technology", "computer human", "mis quarterly", "electornic commerce",
"j market", "telematics and informatics", "telematics informatics", "retail consumer",
"international volume", "international business", "global information",
"et", "al", "al.", "tam", "sem", "pls", "utaut", "tpb",
".com", "management", "marketing", "published", "study",
"research", "literature", "model", #from journal information
"app", "application", "usage"])
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()Set up.
So, I need a few functions as set up for cleaning the text. Function extract_text_from_pdf() is using PyMuPDF to extract text from a PDF file.
#version one using PyMuPDF
def extract_text_from_pdf(filename):
text = ""
try:
doc = fitz.open(filename)
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
text += page.get_text()
except Exception as e:
print(f"Error reading {filename}: {e}")
return textThis function is just one of the data cleaning functions: For Topic modeling, I write a function to generate dictionaries and save them in a .mm file format.
def generate_dictionary(text, name):
"""
As input takes in the text to build the dictionary for and the name of a .mm file
"""
dictionary = Dictionary(text)
corpus = [dictionary.doc2bow(review) for review in text]
filename = f"{name}.mm"
MmCorpus.serialize(filename, corpus)
return dictionary, corpusAdditionally, I want a function that prints the top 50 most frequently appearing words in the corpus:
I also plan on seeing how python clusters the words (as in, finds similar words) vs me: This is a function for if you want to use a word embedding (requires some effort, time and machine power!):
def get_embedding(text):
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model_bert = BertModel.from_pretrained('bert-base-uncased')
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True, max_length=20)
with torch.no_grad():
outputs = model_bert(**inputs)
return outputs.last_hidden_state.mean(dim=1).squeeze().numpy()And then you use this to get semantically similar words:
def get_semantically_similar_words(words, threshold=0.7):
similar_words = set(words)
for word in words:
token = nlp(word)
for vocab_word in nlp.vocab:
if vocab_word.has_vector and vocab_word.is_alpha:
similarity = token.similarity(nlp(vocab_word.text))
if similarity >= threshold:
similar_words.add(vocab_word.text)
return similar_wordsSo, how do I find the themes? Essentially, I just tweaked TF-IDF:
class CustomTfidfVectorizer(TfidfVectorizer):
def __init__(self, vocabulary=None, **kwargs):
super().__init__(vocabulary=vocabulary, **kwargs)
#self.general_keywords = set(general_keywords)
def build_analyzer(self):
analyzer = super().build_analyzer()
return lambda doc: [w for w in analyzer(doc)] #if w not in self.general_keywords]
def fit(self, raw_documents, y=None):
self.fit_transform(raw_documents, y)
return self
def fit_transform(self, raw_documents, y=None):
X = super().fit_transform(raw_documents, y)
self.max_frequencies = self._compute_max_frequencies(X, raw_documents)
return X
def transform(self, raw_documents):
X = super().transform(raw_documents)
# Calculate augmented term frequency
max_frequencies = self.max_frequencies
max_frequencies[max_frequencies == 0] = 1 # Avoid division by zero
augmented_tf = 0.5 + 0.5 * (X.toarray() / max_frequencies[:, None])
# Penalize general keywords
#penalized_idf = self.idf_ * (1 - 0.8 * np.isin(self.get_feature_names_out(), list(self.general_keywords)))
# Apply penalized IDF
augmented_tfidf = augmented_tf * penalized_idf
return csr_matrix(augmented_tfidf)
def _compute_max_frequencies(self, X, raw_documents):
max_frequencies = np.zeros(X.shape[0])
for i, doc in enumerate(raw_documents):
term_freq = {}
for term in doc.split():
if term in term_freq:
term_freq[term] += 1
else:
term_freq[term] = 1
max_frequencies[i] = max(term_freq.values())
return max_frequenciesKeyword Analytics
try:
df = pd.read_csv("P2_AR_04.csv", encoding='utf-8')
except UnicodeDecodeError:
try:
df = pd.read_csv("P2_AR_04.csv", encoding='latin-1')
except Exception as e:
error_message = str(e)
df = NoneClean all the data you’ve gathered the same way the PDF’s have been cleaned (the preprocess_text() function looks very similar to the cleaning function above!):
df2 = df.copy()
columns_to_preprocess = ['Man_Theme',
'K1','K2','K3','K4','K5','K6','K7','K8','K9','K10',
'F1','F2','F3','F4','F5','F6','F7','F8','F9',
'FNS1','FNS2','FNS3','FNS4',
'METHOD1','METHOD2','METHOD3','METHOD4',
'THEORY1','THEORY2','THEORY3','THEORY4',
'LIMIT1' ,'LIMIT2' ,'LIMIT3', 'Abstract'
]
for col in columns_to_preprocess:
df2[col] = df2[col].apply(preprocess_text)papers = {}
for paper_id, filename in name_of_pdfs.items():
text = extract_text_from_pdf(filename)
papers[paper_id] = text
papers_df = pd.DataFrame.from_dict(papers, orient = 'index', columns = ['paperText'])
papers_df = papers_df.reset_index(names = ['paperID'])
papers_df.to_csv('papers_unclean.csv')
papers_df.head()These look like this: 
# keep a copy (a habit of mine)
papers_uncleaned = papers.copy()
theme_of_words_uncleaned = theme_of_words.copy()
# clean up all papers
papers_cleaned = preprocess_Dict(papers)
papersClean_df = pd.DataFrame.from_dict(papers_cleaned, orient = 'index', columns = ['paperText'])
papersClean_df = papersClean_df.reset_index(names = ['paperID'])
papersClean_df.to_csv('papers_clean3.csv')
papersClean_df.head()
Clean the theme of words dictionary so the words match:
theme_of_words_cleaned = {}
for k, v in theme_of_words.items():
theme_of_words_cleaned[k] = preprocess_list(v)
theme_of_words_cleaned['psychological'][:10][‘initial trst’,‘simcong’,‘hedmotiv’,‘selfefficacy’,‘strss’,‘controlled motiv’,‘cong’,‘selfcong cong’,‘trst systems’,‘custom loyalti’]
Make sure to drop all NA’s and empty values:
for k, v in theme_of_words_cleaned.items():
theme_of_words_cleaned[k] = [x for x in v if x not in [None, "", ' ', 'NaN'] and not (isinstance(x, float) and math.isnan(x))]Themes Based on Count of Words in Each Group
I will skip the parts on BERT and word embeddings that’s in the jupyter notebook as these were not used for my project. The reason is that it was taking so long and my computer simply did not have the capacity to handle it. I also didn’t have the time to find a fix for it, but there are a bunch of commented-out code from chatGPT that I was playing around with.
So, we now have a dictionary with the factors and their theme, and a corpus of text of all papers in the dataset. What I’m going to do here is:
- Count all the words
total_wordsin each paper - Count the instances of each word (factor) in
theme_of_words_cleanedin each paper - Each word’s count adds 1 point to its corresponding theme’s “weight score”
- Take for example the word emotion and I said the theme for this word is psychological. If emotion shows up 10 times in paper 1, paper 1’s dictionary of weights has a weight of 10 for (divided by the total number of words) psychological.
results = []
count_words_df = pd.DataFrame(results)
for doc_id, text in papers_cleaned.items():
doc = nlp(text)
word_counts = defaultdict(int)
for token in doc:
for group, keywords in theme_of_words_cleaned.items():
if token.text.lower() in keywords:
word_counts[group] += 1
total_words = len(doc)
group_weights = {f"{group}_w": count / total_words for group, count in word_counts.items()}
max_weight = max(group_weights.values(), default=0)
theme = max(group_weights, key=group_weights.get).replace("_w", "") if max_weight > 0 else None
result = {"doc_id": doc_id, **word_counts, **group_weights, "theme": theme, "max_weight": max_weight}
results.append(result)
for group in theme_of_words_cleaned.keys():
if group not in count_words_df.columns:
count_words_df[group] = 0
if f"{group}_w" not in count_words_df.columns:
count_words_df[f"{group}_w"] = 0.0
count_words_df.head()
This is still very basic, though because it’s only based on the factors which may not be fully representative. So, I do this again using keywords in addition to the factors. These are keywords that were selected by the authors as well as information extracted from Web of Science \BibTeX file.
cols_toPick = ['K1','K2','K3','K4','K5','K6','K7','K8','K9','K10','F1','F2','F3','F4','F5','F6','F7','F8','F9']
keywordsDf = df2.loc[:,cols_toPick]
# flatten the dataframe to a list
keywords_across_db = keywordsDf.values.flatten().tolist()
# there are 2,717 words here
print("number of words (factors and keywords) in total ", len(keywords_across_db))
# making sure there are no empty/NaN/Null values
keywords_across_db = [x for x in keywords_across_db if x not in [None, "", ' ', 'NaN'] and not (isinstance(x, float) and math.isnan(x))]
# making sure there are no duplicates (set takes care of this)
keywords_across_db_nodup_cleaned = list(set(keywords_across_db))
# convert the list into a dictionary temporarily, then convert it to a dataframe
temp = {'Keyword': keywords_across_db_nodup_cleaned}
keywords_themes_df = pd.DataFrame(temp, columns=['Keyword'])
# go back to the theme_of_words_cleaned and find each keyword's theme
keywords_themes_dic = {keyword: theme for theme, keywords in theme_of_words_cleaned.items() for keyword in keywords}
# This is just a dataframe view of the keywords with their respective theme
keywords_themes_df['Theme'] = keywords_themes_df['Keyword'].map(keywords_themes_dic)
# if the theme is empty, give it "Generic" - that means these keywords weren't in the list of important words that we picked themes for
keywords_themes_df['Theme'] = keywords_themes_df['Theme'].apply(lambda x: 'Generic' if pd.isna(x) or x == ' ' else x)
keywords_themes_df.head()
I’m gonna get rid of all the Generic keywords, so keeping a copy of this dataframe:
keywords_themes_df_withGenerics = keywords_themes_df.copy()
keywords_themes_df['Theme'] = keywords_themes_df['Theme'].apply(lambda x: 'Generic' if pd.isna(x) or x == ' ' else x)
# everything but generic
keywords_themes_df = keywords_themes_df.loc[keywords_themes_df['Theme'] != 'Generic']
# flatten it to build a vocabulary
words_acrossAll_nonGeneric = keywords_themes_df['Keyword'].values.flatten().tolist()
# making sure no null values were generated
words_acrossAll_nonGeneric = [x for x in words_acrossAll_nonGeneric if x not in [None, "", ' ', 'NaN'] and not (isinstance(x, float) and math.isnan(x))]
# making sure there are no dulicates (233 words total)
words_acrossAll_nonGeneric = list(set(words_acrossAll_nonGeneric))Theme Assignment
I will now use the custom TF-IDF class to generate a TF-IDF matrix. This is similar to what I did by hand a bit further above. Basically, all TF-IDF is doing is counting the frequency of words across the document.
vectorizer_keys = CustomTfidfVectorizer(vocabulary = words_acrossAll_nonGeneric)
tfidf_matrix = vectorizer_keys.fit_transform(papers_cleaned.values())
tfidf_df = pd.DataFrame(tfidf_matrix.toarray(), index = papers_cleaned.keys(), columns=vectorizer_keys.get_feature_names_out())
tfidf_df.head()
Now using TF-IDF scores, finding the weights for themes for each paper:
keyword_to_theme = {keyword: theme for theme, keywords in theme_of_words_cleaned.items() for keyword in keywords}
theme_weights = pd.DataFrame(0, index=tfidf_df.index, columns=theme_of_words_cleaned.keys())
for keyword, theme in keyword_to_theme.items():
if keyword in tfidf_df.columns:
theme_weights[theme] += tfidf_df[keyword]
for _, row in df2.iterrows():
paper_id = row['ID']
keywords = words_acrossAll_nonGeneric
for keyword in keywords:
if keyword in tfidf_df.columns:
theme = keyword_to_theme.get(keyword, None)
if theme:
#if theme in tfidf_df.index:
theme_weights.at[paper_id, theme] += tfidf_df.at[paper_id, keyword] * 5
# this is picking just 1 theme per paper - find the theme with the maximum weight as the main theme of the paper
main_theme_df = theme_weights.apply(lambda row: (row == row.max()).astype(int), axis=1)
main_theme_df.head()
Visualizing this:
fig, axes = plt.subplots(nrows=2, ncols=1, figsize=(20, 10))
# Heatmap for theme weights
sns.heatmap(theme_weights.T, ax=axes[0], cmap="YlGnBu_r", cbar_kws={'label': 'Weight'})
axes[0].set_xlabel("Paper ID")
axes[0].set_ylabel("Theme")
axes[0].set_title("Theme Weights per Paper")
# Heatmap for main themes
sns.heatmap(main_theme_df.T, ax=axes[1], cmap="YlGnBu_r", cbar_kws={'label': 'Theme Presence'})
axes[1].set_xlabel("Paper ID")
axes[1].set_ylabel("Theme")
axes[1].set_title("Main Theme per Paper")
plt.tight_layout()
plt.show()
plt.savefig('main_themes_heatmap_1.png')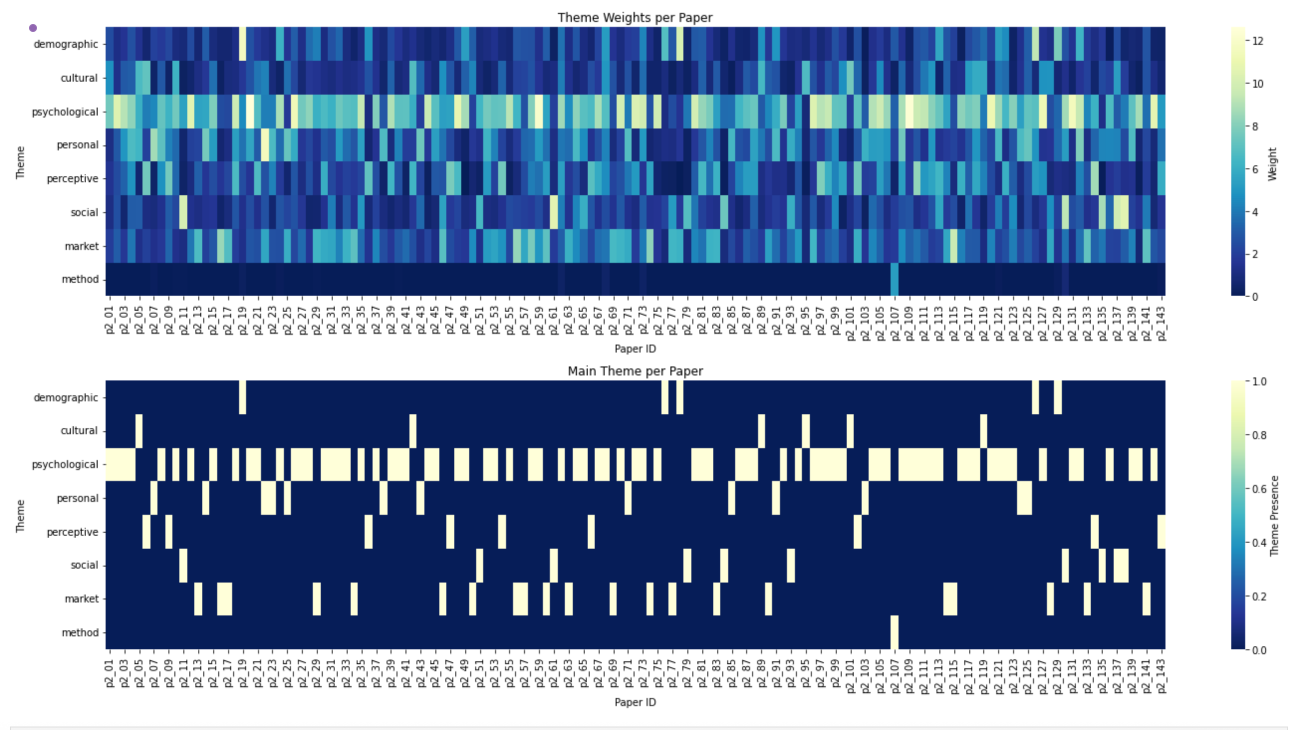
To extract the themes easily:
# Extract themes for each paper
themes_for_papers = {
paper_id: main_theme_df.columns[row.astype(bool)].tolist()
for paper_id, row in main_theme_df.iterrows()
}
# Print the themes for each paper
for paper_id, themes in themes_for_papers.items():
print(f"Paper ID: {paper_id}, Themes: {', '.join(themes)}")Paper ID: p2_01, Themes: psychological
Paper ID: p2_02, Themes: psychological
Paper ID: p2_03, Themes: psychological
Paper ID: p2_04, Themes: psychological
Paper ID: p2_05, Themes: psychological
Paper ID: p2_06, Themes: perceptive
Paper ID: p2_07, Themes: personal
Paper ID: p2_08, Themes: personal
Paper ID: p2_09, Themes: perceptive
Paper ID: p2_10, Themes: psychological
Since Topic Modeling is Multimembership, papers can have more than just 1 theme. Since I didn’t use a word embedding and may not get the best representatitve theme here, I decided to allow for up to 3 themes. To do this, I changed the CustomTfidfVectorizer class.
ALLOWING FOR MULTIPLE THEMES
class CustomTfidfVectorizerUpdateClass(TfidfVectorizer):
def __init__(self, theme_keywords, threshold=0.8, **kwargs):
# Generate vocabulary from theme_keywords
vocabulary = list(set(word for words in theme_keywords.values() for word in words))
super().__init__(vocabulary=vocabulary, **kwargs)
self.threshold = threshold # Threshold for determining multiple themes
self.theme_keywords = theme_keywords # Store theme_keywords for later use
def build_analyzer(self):
analyzer = super().build_analyzer()
return lambda doc: [w for w in analyzer(doc)]
def fit(self, raw_documents, y=None):
self.fit_transform(raw_documents, y)
return self
def fit_transform(self, raw_documents, y=None):
X = super().fit_transform(raw_documents, y)
self.max_frequencies = self._compute_max_frequencies(X, raw_documents)
return X
def transform(self, raw_documents):
X = super().transform(raw_documents)
# Calculate augmented term frequency
max_frequencies = self.max_frequencies
max_frequencies[max_frequencies == 0] = 1 # Avoid division by zero
augmented_tf = 0.5 + 0.5 * (X.toarray() / max_frequencies[:, None])
augmented_tfidf = augmented_tf # No penalized IDF applied here
return csr_matrix(augmented_tfidf)
def determine_themes(self, documents_dict):
"""
Determines the themes for each document based on TF-IDF scores.
A paper can have multiple themes if the scores are within the threshold.
:param documents_dict: Dictionary of documents (keys: IDs, values: text)
:return: Dictionary where keys are document IDs and values are lists of themes
"""
document_ids = list(documents_dict.keys())
raw_documents = list(documents_dict.values())
X = self.transform(raw_documents).toarray()
feature_name_to_index = {name: i for i, name in enumerate(self.get_feature_names_out())}
theme_scores = {}
for doc_index, doc_vector in enumerate(X):
doc_id = document_ids[doc_index]
# Calculate scores for each theme
scores = {
theme: sum(doc_vector[feature_name_to_index[word]]
for word in keywords if word in feature_name_to_index)
for theme, keywords in self.theme_keywords.items()
}
max_score = max(scores.values()) if scores else 0
# Determine themes within the threshold
selected_themes = [
theme for theme, score in scores.items()
if score >= self.threshold * max_score
]
theme_scores[doc_id] = selected_themes
return theme_scores
def _compute_max_frequencies(self, X, raw_documents):
max_frequencies = np.zeros(X.shape[0])
for i, doc in enumerate(raw_documents):
term_freq = {}
for term in doc.split():
if term in term_freq:
term_freq[term] += 1
else:
term_freq[term] = 1
max_frequencies[i] = max(term_freq.values())
return max_frequenciesSimilar to the above task, I generate the vectorizer from theme_of_words_cleaned vocabulary, but this time, allow for a few more themes (threshold = 0.75).
vectorizer_keys2 = CustomTfidfVectorizerUpdateClass(theme_keywords = theme_of_words_cleaned, threshold = 0.75)
tfidf_matrix2 = vectorizer_keys2.fit_transform(papers_cleaned.values())
tfidf_df2 = pd.DataFrame(tfidf_matrix2.toarray(), index=papers_cleaned.keys(), columns=vectorizer_keys2.get_feature_names_out())
tfidf_df2.head()
You can still pick a main theme for each paper, but I want to see the top 3 themes:
keyword_to_theme2 = {keyword: theme for theme, keywords in theme_of_words_cleaned.items() for keyword in keywords}
theme_weights2 = pd.DataFrame(0, index=tfidf_df2.index, columns=theme_of_words_cleaned.keys())
for keyword, theme in keyword_to_theme2.items():
if keyword in tfidf_df2.columns:
theme_weights2[theme] += tfidf_df2[keyword]
for _, row in df2.iterrows():
paper_id = row['ID']
#for keyword in words_acrossAll_nonGeneric:
for keyword in vectorizer_keys2.get_feature_names_out():
if keyword in tfidf_df2.columns:
theme = keyword_to_theme2.get(keyword, None)
if theme:
# the 5 I'm adding here is just to make the weights a bit larger for visualization. It's a simple scaling and won't change the results
theme_weights2.at[paper_id, theme] += tfidf_df2.at[paper_id, keyword] * 5
top_3_themes_for_papers = {
paper_id: theme_weights2.loc[paper_id]
.sort_values(ascending=False)[:3]
.index.tolist()
for paper_id in theme_weights2.index
}
for paper_id, themes in top_3_themes_for_papers.items():
print(f"Paper ID: {paper_id}, Top 3 Themes: {', '.join(themes)}")Paper ID: p2_01, Top 3 Themes: psychological, cultural, demographic
Paper ID: p2_02, Top 3 Themes: psychological, market, personal
Paper ID: p2_03, Top 3 Themes: psychological, personal, perceptive
Paper ID: p2_04, Top 3 Themes: psychological, personal, perceptive
Paper ID: p2_05, Top 3 Themes: cultural, personal, psychological
Paper ID: p2_06, Top 3 Themes: perceptive, cultural, psychological
Paper ID: p2_07, Top 3 Themes: personal, psychological, demographic
Paper ID: p2_08, Top 3 Themes: psychological, personal, perceptive
Paper ID: p2_09, Top 3 Themes: perceptive, psychological, personal
Paper ID: p2_10, Top 3 Themes: psychological, cultural, personal
Keep a copy and save this to file:
df3 = df2.copy()
top_3_themes_for_papers = {
paper_id: ", ".join(theme_weights2.loc[paper_id]
.sort_values(ascending=False)[:3]
.index.tolist())
for paper_id in theme_weights2.index
}
df3["Algo_Theme"] = df2["ID"].map(top_3_themes_for_papers)
df3.to_csv("NewWithThemes.csv")